Risk identification is the first step in the proactive risk management process. It provides the opportunities, indicators, and information that allows an organization to raise major risks before they adversely affect operations and hence the business.
This step is closely related to the Information Technology Infrastructure Library (ITIL) term "classification"-formally identifying incidents, problems, and known errors by origin, symptoms, and causes.
Risk Statements
Before a risk can be managed, the operations staff must clearly and consistently express it in the form of a risk statement.
A risk statement is a natural language expression of a causal relationship between a real, existing state of affairs or attribute, and a potential, unrealized second event, state of affairs, or attribute. The first part of the risk statement is called the condition and provides the description of an existing state of affairs or attribute that operations feels may result in a loss or reduction in gain.
The second part of the risk statement is a second natural language statement called the consequence and describes the undesirable attribute or state of affairs. The two statements are linked by a term such as "therefore" or "and as a result" that implies an uncertain (less than 100 percent) but causal relationship. The two-part formulation process for risk statements has the advantage of coupling the risk consequences with observable (and potentially controllable) risk conditions early in the risk identification stage.
Root Cause
When formulating a risk statement, the operations staff should consider the root cause or originating source, of the risk condition. Understanding root causes can help to identify additional, related risks. There are four main sources of risk in IT operations:
- People - Even if a group's processes and technology are
flawless, human actions (whether accidental or deliberate) can put
the business at risk.
- Process - Flawed or badly documented processes can put
the business at risk even if they are followed perfectly.
- Technology - The IT staff may precisely follow a
perfectly designed process, yet fail to meet business goals because
of problems with the hardware, software, and so on.
- Environment - Some factors are beyond the IT group's
control but can still affect the infrastructure in a way that harms
the business. Natural events such as earthquakes and floods fall
into this category, as do externally generated, man-made problems,
such as civil unrest or changes to government regulations.
These are broad categories, and they can easily overlap. For example, if a newly hired operator undergoes training on the backup software and a week later makes a mistake that causes the backup to fail, is the source of risk "people" or "process?" There are many ways to decide which category a risk fits in, but it is more important to define one way and stick to it, rather than spend time seeking the "perfect" way.
Downstream Effect
The risk identification process results in the identification of the outcome, or downstream effect, of the risk. Understanding downstream effects (total loss or opportunity cost) can help in correctly evaluating the impact that the consequence will have on an organization. There are four main ways in which operational risk consequences can affect the business:
- Cost - The infrastructure can work properly, but at too
high a cost, causing too little return on investment
(ROI).
- Performance - The infrastructure can fail to meet users'
expectations, either because the expectations were unrealistic, or
because the infrastructure performs incorrectly. The reliability of
a system can also affect the users' perceptions of the service's
performance.
- Capability - The infrastructure can fail to provide the
platform or the components needed for end-to-end services to
function properly or even function at all. For example, consider an
enterprise e-mail system that relies upon mail servers, storage
servers, gateways or message transfer agents (MTAs), network
components, and desktop components. A failure in any one of these
components would affect the e-mail service and hence impact the
business' capability to communicate effectively.
- Security - The infrastructure can harm the business by
not providing enough protection for data and resources, or by
enforcing so much security that legitimate users cannot access data
and resources.
Understanding the characteristics of downstream effect is critical later in the risk identification process when ranking risks to ensure that the most important ones get the attention they deserve since a risk may have a high operational consequence but a low downstream effect, or vice versa.
The following figure schematically depicts the risk identification process along with an example.
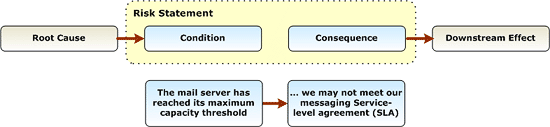
Risks List
The minimum output from risk identification activities is a clear, unambiguous, consensus statement of the risks being faced by the IT operations staff, which is recorded as a risks list. The risk identification step frequently generates a large amount of other useful information, including the identification of root causes and downstream effects, affected service, owner, and so forth.
An example of a risks list produced during the identification step is depicted in the following table. The risks list in tabular form is the main input for the next stage (analysis) of the risk management process and will become the master risks list used during the subsequent management process steps.
Table: Example Risks List
| Root cause | Condition | Consequence | Downstream effect |
|---|---|---|---|
|
Inadequate staffing |
The service desk cannot handle the number of calls it is receiving. |
The SLA will not be met and customers will have to wait longer for support. |
Reduced customer satisfaction. |
|
Technology change |
CRM software vendor plans to withdraw support for the current version of the product. |
Existing CRM system will be unsupported. |
Reduced sales force capabilities because IT cannot develop the requested enhancements or make any system changes. |
|
New regulatory requirement |
All e-mails and attachments need to be stored for eleven years. |
Current backup and archiving software cannot accommodate this need. |
May result in trading restrictions being imposed and negatively affect the organization's position and image in the market. |
Best Practices
These best practices will be beneficial during the risk identification step.
Review Risk Lists and Lessons Learned
A great deal can be learned from reviewing risk databases from similar tasks, talking to process owners about risk management activities in their areas, and reading case studies that identify risks to services or processes. An optimized and mature risk management discipline involves capturing knowledge and best practices from operational activities through the application of such basic knowledge management techniques as consistent taxonomy, risk classification, document management, and advanced search capabilities.
Continual Identification
When a group adopts risk management, the first step is often a brainstorming session to identify risks. Identification does not end with this meeting. Identification happens as often as changes are able to affect the IT infrastructure-which is to say, identification happens every day.
Discussions
Identification discussions are very important. A key to their success is to represent all relevant viewpoints, including stakeholders as well as different segments of the operations staff. This is a powerful way to expose assumptions and differing viewpoints. The ultimate goal of the identification discussion is to improve the organization's risk management capability.
Cause-Effect Matrix
The set of all possible conditions is nearly infinite, and the sheer volume can make it difficult for the operations staff to focus on one at a time, especially during brainstorming. An effective solution, and one that has benefits later in the process, is to subdivide all of the possible conditions into a table with one row for each of the four causes of risk and one column for each of the four types of downstream effect.

It is now much easier to focus on one cell of the table at a time. For example, IT operations staff might ask themselves, "How might people in the operations group make mistakes that would cause us to do the right work at too high a cost?" Or they might ask, "How could our technology fail to meet customers' performance expectations?" Or more specifically, "How might hardware problems cause the sales group's order entry system to bog down?"
Risk Statement Form
A helpful way to present the information gathered during this step is through a risk statement form, which may add information that will be valuable later during the risk tracking step. In addition to the four parts of the risk statement (root cause, condition, consequence, and downstream effect), a statement form including the following can be very useful:
- Role or function - The service management function (SMF)
most directly involved with the risk situation.
- Related service - Service most affected by the
risk.
- Context - A paragraph containing additional background
information that helps to clarify the risk situation.
- Related risks and dependencies among risks - Identify
where the consequences of a risk may also be the root cause of or
have a direct impact on other risks.