The Supporting Quadrant includes the processes, procedures, tools, and staff required to identify, assign, diagnose, track, and resolve incidents, problems, and user/customer requests within the approved requirements delineated in the service level agreement (SLA).
Goal and Objectives
The key goal of the Supporting Quadrant is the timely resolution of these incidents, problems, and inquiries for end users of the IT services provided. The service management functions (SMFs) within this quadrant achieve this goal through the following objectives:
- Ensure that both reactive and proactive functions are in place
to manage service levels.
- Prioritize the service desk's focus on meeting customer needs
and business requirements.
- Work with the Operating Quadrant's SMFs in monitoring for
issues before they affect the user.
The reactive functions depend on an organization's ability to respond and resolve incidents and problems quickly. The more desirable, proactive functions try to avoid any disruption in service in the first place by identifying root causes and resolving problems before any service levels are impacted. This is primarily achieved through effective monitoring of the service solution against predefined thresholds and by giving the operations staff time to resolve potential problems before they manifest into service disruptions. Although the Microsoft Operations Framework (MOF) defines these support processes in the Supporting Quadrant, they are an integral part of the daily functioning of every other quadrant, particularly of the Operating Quadrant, in tracing problems to their root cause.
Team Model Role Cluster
The Support Role Cluster in the MOF Team Model is the role cluster most closely involved in implementing and facilitating the Supporting Quadrant SMFs. However, with the addition of the Service Role Cluster (in MOF version 3.0), the two role clusters (Service and Support) could potentially both be involved in the Supporting Quadrant SMFs. For example, the Service Role Cluster owns the overall end-to-end management of a specific service, such as the provisioning of a messaging service solution across the organization, which would include the operations representation in the design and deployment of the solution as well as the operations aspects of the solution. The Support Role Cluster would work closely with the Service Role Cluster in this case and would focus specifically on the service level and user support of the messaging solution.
Operations Management Review
The SLA Review is the operations management review that assesses the effectiveness of the IT operations group in delivering the agreed-upon service levels contained in the mutually approved (by both the customer and IT) SLA. This review focuses its assessment on the delivery of services to the customer and end users and is complementary to the Operations Review discussed earlier. Whereas the Operations Review focuses on internal operational efficiencies, the SLA Review focuses on external end-user service levels and any changes required to address inadequacies in these services.
We recommend that customers, end users, and the operations staff use the SLA Review on a regularly scheduled basis (for example, monthly or quarterly) to monitor service delivery and to identify changes required in service levels, system functionality, new business requirements, and/or key process changes.
The SMFs
The Supporting Quadrant includes the following service management functions:
- Service Desk
- Incident Management
- Problem Management
MOF bases these SMFs on the Information Technology Infrastructure Library (ITIL) and extends them to include Microsoft-specific practices and additional industry best practices.
Service Desk
The Service Desk is the overarching service management function of the Supporting Quadrant, which is also reflected in how ITIL refers to the service desk as a "function" rather than as a process, the only exception of its kind in ITIL.
The Service Desk SMF provides guidance on setting up and running the organizational unit or department that is the single point of contact between the users and provider of IT services. It coordinates all activities and customer communications about incidents, problems, and inquiries related to production systems. Requests come to the service desk for help on solving issues and problems across a vast array of applications, communication systems, desktop configurations, and facilities.
The Service Desk SMF focuses on two areas: implementation of the Supporting Quadrant SMFs and optimization of the service desk processes.
Implementation of the Supporting Quadrant SMFs includes:
- Managing the service desk staff.
- Monitoring service desk performance.
- Managing costs and charges.
- Reporting to management.
Optimization of service desk processes includes:
- Comparing actual performance to commitments (for example,
comparing service level metrics with customer and operations teams'
operating level agreements [OLAs] and SLAs) and to industry
benchmarks (such as Help Desk Institute).
- Optimizing headcount and staffing levels.
- Monitoring and continually assessing and improving service desk
workflow and business processes.
- Monitoring and continually assessing and improving tools and
technologies used in automating service desk activities.
Incident Management
Incident management is the process of managing and controlling faults and disruptions in the use or implementation of IT services, including applications, networking, hardware, and user-reported service requests.
The effective management of incidents is a complex process that requires interaction with many other service management functions, most notably the Service Desk, Problem Management, Configuration Management, and Change Management SMFs. Because of this complexity and the need for clear communication about an incident, a robust incident taxonomy has been developed to facilitate incident management. The following list provides the key definitions within this taxonomy as well as summarizes the principle activities within the Incident Management SMF:
- Incident communication - Communicating to the enterprise
the existence of and current status of service-disrupting
incidents.
- Incident control - Ensuring that incidents are resolved
as quickly as possible with minimal impact.
- Incident origin determination - Determining the
infrastructure component or components that are causing the
disruption.
- Incident recording - Ensuring that incidents are
recorded as quickly as possible into the appropriate databases and
support tools.
- Incident alerting - Communicating to all involved in the
incident in order to ensure that action toward resolution is
immediate.
- Incident diagnosis - Accurately determining the nature
and cause of the incidents.
- Incident investigation - Researching to determine if the
incident is unique or has been experienced before.
- Incident support - Providing support throughout the
entire life cycle of the incident in order to resolve the incident
as quickly as possible and with the least impact to business
processes.
- Incident resolution - Resolving the incident as quickly
as possible through the effective use of all appropriate tools,
processes, and resources available.
- Incident recovery - Returning the affected environment
to stability once the incident has been resolved.
- Incident closure - Effecting proper closure of the
incident, ensuring that all pertinent data surrounding the life
cycle of the incident is properly discovered and recorded.
- Incident information management - Properly recording and
categorizing incident-related information for future use by all
levels and organizations within the enterprise.
Problem Management
The key goal for problem management is to ensure stability in service solutions by identifying and documenting errors from the IT infrastructure and either creating a workaround or initiating a request for change (RFC) to resolve or eliminate the root cause (where supported by the business case for doing so). The Problem Management SMF takes the lead in structuring the escalation process of investigation, diagnosis, resolution, and closure of problems.
Problem management is closely interrelated with incident management performed at the service desk level. To better understand this interrelationship, it is necessary to understand the differences between incidents, problems, and known errors. The following table lists these key definitions.
Table: Comparison of Problem Management Terms
| Item | Definition |
|---|---|
|
Incident |
Any event that deviates from the expected operation of a system or service. |
|
Problem |
A condition identified from multiple incidents exhibiting common symptoms, or from a single significant incident, indicative of a single error, for which the cause is unknown. |
|
Known error |
A condition identified by successful diagnosis of the root cause of a problem when it is confirmed which configuration item is at fault and a temporary or permanent fix or workaround is in place. |
The following figure depicts the interrelationship of these items and the resultant connection with the Change Management SMF.
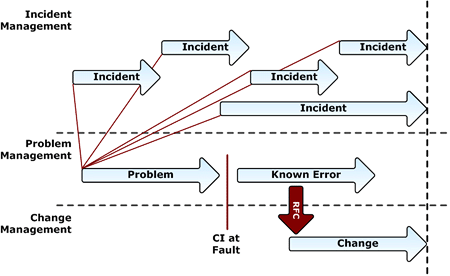
Figure: Incident, problem, and change management relationship
An important aspect of problem management not to be overlooked is that problem management works proactively to prevent problems from occurring. For example, problem management works with availability management to ensure that increased redundancy is built into mission-critical systems and infrastructure components.